
本文将向您展示 Loro 平台实现的富文本 CRDT 算法。该算法符合 Peritext(链接打开新标签页) 对无缝富文本协作的要求,并且能够基于任何列表 CRDT 算法之上,把它们转换成富文本 CRDT。
历史演示
请点击原文查看演示
您看到的是 Loro 富文本 CRDT 的在线演示,它是基于 Quill 技术构建的。通过这个演示,您可以体验到重放编辑过程后的实时协作和离线时的并发编辑功能。此外,您还可以通过拖动历史视图来回放编辑历史。
如果您对 CRDT 这一概念还不太熟悉,我们的文章 CRDT 是什么 为您提供了一个简洁的入门介绍。
背景知识
Loro 的技术基础是 Seph Gentle 提出的 可重放事件图 (REG) 算法。但是,这一算法无法与 Peritext 的原始版本完美结合,这激发了我们开发一种新的富文本算法的想法。这个新算法不依赖于任何特定的列表 CRDT,与 REG 有着良好的兼容性,并在其基础上发展出了富文本 CRDT。
在深入探讨 Loro 富文本 CRDT 的算法之前,我将简要介绍一下 REG 和 Peritext,以及为什么 Peritext 不能直接应用于 REG。
关于列表 CRDT 的概述
关于列表 CRDTs 的回顾
以下是几幅与列表 CRDTs (冲突自由复制数据类型) 相关的插图,可在链接中查看详细内容:
-
列表 CRDTs 的标识 -

列表 CRDTs 的插入操作 -

列表 CRDTs 的删除操作 -

列表 CRDTs 的墓碑机制




重放事件图简介
Seph Gentle(新标签页中打开),重放事件图(REG)的作者,目前正在研究这篇论文,并引起了广泛的关注。
重放事件图(REG)是一种创新的算法,融合了操作转换(OT)和冲突无关数据类型(CRDTs)的优势。它具备 CRDT 的分布式特征,支持点对点(P2P)合作和数据所有权管理。更重要的是,在没有并行编辑发生的情况下,它能像 OT 那样保持极低的运行开销。
无论是实时协作还是跨多个端口的同步,都会形成一个类似 Git 历史记录的有向无环图(DAG),这个图记录了所有并行编辑的历史。REG 算法就是用来记录用户在这个图上的所有编辑历史。
与传统的 CRDTs 不同,REG 只需记录操作的原始描述,而不是复杂的元数据。比如,在文本编辑中,RGA 算法(新标签页中打开) 需要用到左侧字符的操作标识(op ID)和 Lamport 时间戳(新标签页中打开) 来确定插入的具体位置。而 Yjs(新标签页中打开)/Fugue 则需要插入点左右两边字符的操作标识。相比之下,REG 通过记录插入时的索引位置来简化这个过程。采用 Fugue(新标签页中打开) 的 Loro 也继承了这些优势。
需要注意的是,索引并不是一个固定不变的位置标识。例如,当你标记了从 index=x 到 index=y 的内容,如果同时有人在 index=n 处插入了 n 个字符(且 n<x),那么你的标记范围应该相应地调整,变成从 x+n 到 y+n。REG 能通过回溯历史来精确找到这个索引的位置,并据此重建正确的 CRDT 结构。
虽然听起来重建历史可能很耗时,但实际上 REG 可以只回溯部分历史。当需要合并来自远端的更新时,它只需重放与远程更新平行发生的操作,通过应用这些操作到当前文档,就能重新构建本地 CRDTs,并计算出与远程操作应用后的差异。
REG 算法在快速进行本地更新方面表现卓越,同时有效解决了在冲突无处不在的 CRDTs(冲突复制数据类型)系统中处理“墓碑”(即已删除数据的标记)的难题。例如,一旦某个操作在所有节点间完成同步,就不会与其他操作发生冲突,因此可以从历史记录中安全地移除这个操作。
关于 Fugue



关于 Peritext 的浅显介绍
Peritext(点击此处在新标签页中查看) 是 Geoffrey Litt et al. 提出的创新性研究。这是首篇探讨富文本协作实时数据类型(CRDTs)的论文。Peritext 能在合并多用户同时编辑的富文本时,尽可能地保留每位用户的编辑意图。这项技术的核心在于能够融合富文本的各种格式和注释,比如粗体、斜体以及评论等。Peritext 已在 Automerge 和 crdt-richtext 中得到应用。
💡 在同时编辑富文本的情况下,要准确定义“用户意图”并不简单,最好通过具体的例子来理解。
Peritext 解决了几个关键挑战:
首先,它应对了由于样式编辑的冲突而产生的问题。例如,有一段文本:“The quick fox jumped”。如果用户 A 对“The quick”进行加粗处理,而用户 B 对“quick fox jumped”进行加粗,那么理想的合并结果应是整句“The quick fox jumped”都被加粗。但现有的算法可能达不到这个效果,可能导致“The quick fox”或“The”与“jumped”被加粗。
| 原文 | The quick fox jumped |
|---|---|
| A 用户的同时编辑 | The quick fox jumped |
| B 用户的同时编辑 | The quick fox jumped |
| 理想的合并结果 | The quick fox jumped |
| 直接合并 Markdown 文本时的问题示例 | The quick fox jumped |
| 使用 Yjs 时的问题示例 | The quick fox jumped |
此外,Peritext 还处理了样式编辑和文本编辑之间的冲突。在同一个例子中,如果用户 A 对“The quick”加粗,而用户 B 将文本改为“The fast fox jumped”,那么理想的合并应该是“The fast”被加粗。
| 原文 | The quick fox jumped |
|---|---|
| A 用户的同时编辑 | The quick fox jumped |
| B 用户的同时编辑 | The fast fox jumped |
| 理想的合并结果 | The fast fox jumped |
Peritext 特别考虑到了用户对文字样式扩展的不同期望。比如,当你在加粗文本后继续输入时,通常你会希望接下来的文字依然保持加粗状态。但如果你在超链接或评论后输入,你可能不想让新加的内容成为超链接或评论的一部分。

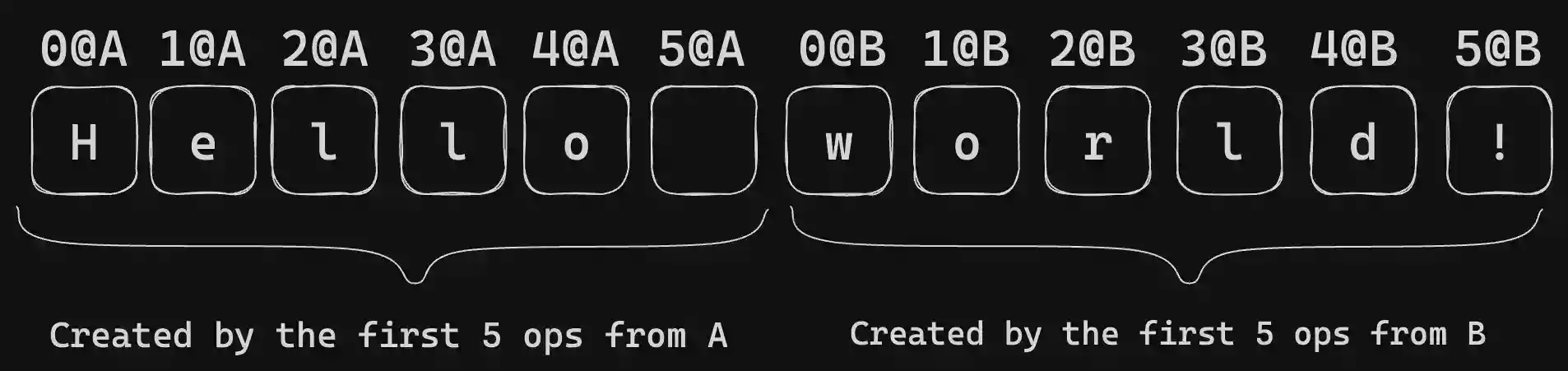
这是 Peritext 内部状态的示意图。它利用字符操作的 ID 来记录不同的样式范围。在这个例子中,加粗样式的范围被定义为 { start: { type: "before", opId: "9@B" }, end: { type: "before", opId: "10@B" }}
原始 Peritext 为什么无法直接与 REG 配合使用
一方面,Peritext 的算法是通过字符的 OpIDs 来定义样式范围的在新标签页中打开,而在没有重现编辑历史的情况下,基于 REG 的 CRDTs 不能准确地识别这些 OpIDs 对应的具体位置。
另一方面,尝试在 REG 中通过重现编辑历史来模拟 Peritext 是不现实的。因为 REG 依赖于一个前提:“无论当前的状态如何,相同的操作都会产生相同的效果”,而 Peritext 并不符合这一标准。比如说,在某个位置 p 插入字符 “x”,”x” 是否加粗,取决于该位置 p 是否已被加粗样式包围,以及“该位置 p 的墓碑中是否含有加粗及其他样式的界限 (在新标签页中打开)。”
Loro 的富文本 CRDT
算法
Loro 通过使用一种特殊的控制字符,称作“样式锚点”,来实现富文本编辑。每一对开始和结束的样式锚点包含以下几点信息:
- 该样式操作的操作 ID
- 样式的键值对
- 样式的 Lamport 时间戳 (新标签页打开),用于标记样式的时间顺序
- 样式扩展行为:决定新插入的文本是否应该继承其周围样式的特性。
要确定一个字符的样式,需要执行以下步骤:
- 找出包括该字符的所有样式锚点对,这些对都是由同一样式操作生成的
- 按照样式的关键词来整理这些对。可能会存在多个有着相同关键词但不同值的样式对。在这种情况下,我们会选择具有最大 Lamport 时间戳的值。如果时间戳相同,那么我们会用对等 ID 来决定采用哪个值。
这种方法与 Yjs 的使用控制字符来实现富文本的方式 (在新标签页中打开)不同。我们的算法是在同一样式操作下,将开始和结束的锚点配对。这样的处理方法能够准确应对多种复杂的文本样式重叠情况:

这些特殊的控制字符对用户是不可见的,每个控制字符在用户看来都是零长度。我们的数据结构能够通过不同的方法来测量文本长度,这对于文本内容的索引非常重要。除了通常的 Unicode、UTF-16 和 UTF-8 编码方式,我们还使用了一种称为“实体长度”的测量方式。这种方式将每个样式锚点视为一个长度为 1 的实体,并且用 Unicode 长度来测量纯文本。

| 概念 | 定义 |
|---|---|
| 风格锚点 | Loro 中用来指示文本风格起始和结束的特殊标记。分为开始和结束两种类型,分别对应风格的开头和结尾。 |
| 富文本元素 | 指一段文本或一个风格锚点。这些元素的集合构成了 Loro 中富文本的内部结构。 |
| Unicode 索引 | 一种定位富文本中文本位置的方式。使用这种方式时,文本长度按照 Unicode 字符计算,而风格锚点则不计入长度。 |
| 实体索引 | 另一种定位富文本中文本位置的方式。这种方法也是以 Unicode 字符计算文本长度,但风格锚点的长度计为 1。 |
本地行为
在特定 Unicode 索引下插入文本时,用户可能有多个选择点。这是因为风格锚点虽然对用户来说没有实际长度,但它们确实存在。

比如说,在 “<b>Hello</b> world” 这个例子中,如果用户想在 Unicode 第 5 个位置插入内容,他们需要决定是在 </b> 标签的左边还是右边插入。如果用户选择了让粗体向前扩展的设置,那么新加入的文字就会被放在 </b> 的左边,使其也成为粗体。
当用户删除文本时,Loro 采用了一种特别的映射方法,以避免误删文本中的风格锚点。
删除特定风格时,系统会添加一个带有空值的新的风格锚点对。
为了优化这一过程,我们可以做出以下调整来去除不必要的风格锚点:
- 删除那些不包含文本的风格锚点。
- 当两种风格相互抵消,例如粗体与非粗体互相覆盖时,我们可以去除相应的风格锚点。
所有这些操作都是在本地完成的,且与 Loro 特定的 List CRDT 算法无关。
在样式交界处插入文字的行为规则
在 Google Doc、Microsoft Word、Notion 等流行的富文本编辑器中,当用户在粗体文本后输入新内容时,这些新内容通常会自动继承粗体样式。但如果在超链接后输入,新内容则不会继承超链接样式。不同的样式对于文字插入位置有不同的偏好,这可能导致冲突。我们在插入新文字时,可以体会到这种自由度的不同。
用户通过 Unicode 索引这样的基于文本的索引与富文本进行交互。由于样式锚点的 Unicode 长度为 0,所以一个含有 n 个样式锚点的 Unicode 索引会提供 n + 1 个潜在的插入位置。
选择插入位置时,我们遵循以下规则:
- 如果某种样式不应向后扩展,则在该样式的开始锚点之前插入。
- 对于粗体等标记的结束,我们在其样式锚点之前插入(扩展方式为“after”或“both”)。
- 对于链接等标记的结束,我们在其样式锚点之后插入(扩展方式为“none”或“before”)。
为避免意外产生新的样式(在新标签页中打开),规则 1 应优先于规则 2 和 3。
当前的处理方法是先向前搜索,找到最后一个符合规则 1 和 2 的位置,然后再向后搜索,找到第一个符合规则 3 的位置。
处理远程更新的合并问题
Loro 把样式锚点当作特殊元素,使用 List CRDT 方法来解决并发冲突。这种处理富文本的逻辑与特定的 List CRDT 算法无关,因此可以采用任何 List CRDT 算法来合并远程操作。Loro 采用的是Fugue(在新标签页中打开) List CRDT 算法。
当远程更新插入新的样式锚点时,相应地会添加新的样式;反之,如果删除了旧的样式锚点,则相应的旧样式也会被移除。
实现强大的最终一致性
这个算法的内部状态由文本段落和样式锚点组成的元素列表构成,而富文本文档就是基于这个内部状态生成的。
通过采用上游的 List CRDT,算法的内部状态能够实现强大的最终一致性。这意味着,即使在不同的环境中进行更新,只要内部状态相同,最终生成的富文本文档也会是一致的。
因此,相同的更新操作将会产生相同的富文本文档,从而证明了这个算法在实现强大的最终一致性方面的有效性。
Peritext 中的评判标准
Peritext 论文 (opens in a new tab) 详细说明了如何在富文本内联格式中保留原意进行内容合并。Loro 的富文本算法已成功通过了该论文中提出的所有测试场景。
1. 同时进行的格式化和插入
| 名称 | 文本 |
|---|---|
| 原始文本 | Hello World |
| 并行操作 A | Hello World(加粗) |
| 并行操作 B | Hello New World(插入新文字) |
| 预期的变化 | Hello New World(插入并加粗) |
Loro 能够轻松处理这一情况,它把文本中的格式标记(比如加粗)视为特殊元素,与文字并列处理。
2. 格式化的重叠
| 名称 | 文本 |
|---|---|
| 原始文本 | Hello World |
| 并行操作 A | Hello World(前半部分加粗) |
| 并行操作 B | Hello World(后半部分加粗) |
| 预期的变化 | Hello World(全文加粗) |
这个案例我们之前已经分析过了。由于格式标记包含了样式操作的标识信息,我们可以识别出两个加粗区域:一个从第 0 个字符到第 5 个字符,另一个从第 3 个字符到第 11 个字符,这使得我们能够将它们合并。
| 名称 | 文本 |
|---|---|
| 原始文本 | Hello World |
| 并行操作 A | Hello World(前半部分加粗) |
| 并行操作 B | Hel_lo World_(斜体处理) |
| 预期的变化 | Hel_lo_ World(部分加粗和斜体) |
支持多种格式样式变化也不在话下。
| 名称 | 文本 | 注释 |
|---|---|---|
| 原始文本 | Hello World | |
| 并行操作 A | Hello World 然后 Hello World(先加粗,后取消加粗) | |
| 并行操作 B | Hello World(部分加粗) | |
| 预期的变化 | Hello World 或 Hello World(部分加粗或全文加粗均可) |
我们像 Peritext 一样,通过添加一个新的 bold 样式(值为 null)来实现取消加粗。每个字符上每个样式键的最终效果,是由包含该字符的时间戳最新的样式决定的。这种方法让我们能够轻松应对这类情况。
3. 在边界处插入文本
在一段粗体文本之后插入的新文本,也应呈现为粗体。

但是,若在链接文本之后进行插入,新加入的文本则不应包含超链接的样式。

4. 支持重叠效果的样式
重叠样式的挑战在于我们应该如何有效地表示它们。在 Loro 中,我们采用了 Quill’s Delta(在新标签页中打开)格式来展现富文本。
[ { insert: 'Gandalf', attributes: { bold: true } }, { insert: ' the ' }, { insert: 'Grey', attributes: { color: '#cccccc' } }]
这里有一个使用 Quill’s Delta 格式的例子
然而,这种格式无法处理同一个键被分配了多个值的情况,使得表达重叠样式变得相当棘手。
例如,如上图所示,当文本“fox”同时被 Alice 和 Bob 所评论时,我们无法直接使用 Quill’s Delta 格式来表示这种重叠。为了解决这个问题,我们可以采取以下两种方法:
将属性值转换为列表
[ { insert: "The ", attributes: { comment: [{ ...commentA }] } }, { insert: "fox", attributes: { comment: [{ ...commentA }, { ...commentB }] }, }, { insert: " jumped", attributes: { comment: [{ ...commentB }] } },]
或使用创建该操作的 op ID 作为属性键
[ { insert: "The ", attributes: { "id:0@A": { key: "comment", ...commentA } } }, { insert: "fox", attributes: { "id:0@A": { key: "comment", ...commentA }, "id:0@B": { key: "comment", ...commentB }, }, }, { insert: " jumped", attributes: { "id:0@B": { key: "comment", ...commentA } }, },]
但这两种方法都需要对 CRDT 库和应用程序代码进行特殊处理,这是一项挑战。
最终,我们找到了一种理想的解决方案:通过使用 <key>: 作为前缀,并让用户为其添加一个独特的后缀来创建区别于其他的样式键。这种方法不仅简化了 CRDT 库的代码(不再需要处理特殊情况),而且能有效应对多重评论重叠的情况,同时也使得应用程序的编码更加用户友好。
[ { insert: "The ", attributes: { "comment:alice": "Hi" } }, { insert: "fox", attributes: { "comment:alice": "Hi", "comment:bob": "Jump" }, }, { insert: " jumped", attributes: { "comment:bob": "Jump" } },]
接下来,我们来看看 Loro 中这一方法的示例代码:
const doc = new Loro();doc.configTextStyle({ comment: { expand: "none", }})const text = doc.getText("text");text.insert(0, "The fox jumped.");text.mark({ start: 0, end: 7 }, "comment:alice", "Hi");text.mark({ start: 4, end: 14 }, "comment:bob", "Jump");expect(text.toDelta()).toStrictEqual([ { insert: "The ", attributes: { "comment:alice": "Hi" }, }, { insert: "fox", attributes: { "comment:alice": "Hi", "comment:bob": "Jump" }, }, { insert: " jumped", attributes: { "comment:bob": "Jump" }, }, { insert: ".", }])
Loro 富文本算法的实现
接下来是截至 2024 年 1 月,Loro 富文本算法实现的简要概述。
Loro 架构简介
Loro 的设计遵循了重放事件图 (Replayable Event Graph) 的特性,内部主要依赖 OpLog 和 DocState 这两个状态。
OpLog 负责记录操作历史,而 DocState 则仅保存当前文档的状态,不涉及历史操作数据。在处理来自远程的更新时,Loro 会从 OpLog 中提取相关操作,并通过 DiffCalculator 工具来计算差异。接着,这些差异会被应用到 DocState 上。这种架构设计也方便了时间旅行功能的实现。
想要了解更多信息,可以参考 DocState 和 OpLog 的文档(新标签页中打开)。

Loro 富文本 CRDT 的实现
在处理富文本方面,Loro 采用了与其列表功能相同的 DiffCalculator 技术,这一技术基于 Fugue 算法(链接将在新标签页中打开)。因此,处理富文本的核心逻辑主要集中在 DocState 中,涵盖了设置文本样式、插入新字符以及多种索引方式的表示。
在展现富文本状态时,我们主要使用两种数据结构:一是 ContentTree,用于表述文本内容和样式的锚点;二是 StyleRangeMap,用于表述不同的文本样式。

这两种结构都是基于一种名为 B+ 树 的技术构建的。
ContentTree 负责高效地查找、插入和删除文本。它能够根据 Unicode/UTF-8/UTF-16/实体索引来定位特定的插入或删除点,但它本身并不存储文本段落的具体样式信息。
我们利用自己的 generic-btree 库(链接将在新标签页中打开) 构建了一种 B+ 树结构,用于在内存中存储和处理文本数据:
- B+ 树的内部节点会记录其子树包含的 Unicode 字符长度、UTF-16 长度、UTF-8 长度以及实体长度。这里的实体长度指的是,如果是样式锚点,则计为 1,否则为 0。
- B+ 树的叶节点则存储文本内容或样式锚点。
StyleRangeMap 则专注于样式范围的高效更新和查询。
在表示样式的 StyleRangeMap B+ 树中:
- 每个内部节点会存储其子树的实体长度。
- 每个叶节点则存储对应文本范围的样式信息集合及其实体长度。
将文本的 ContentTree 和样式的 StyleRangeMap 分开设计,是为了更好地优化性能。在富文本处理中,样式信息通常较为简单且连续,例如,几段文本可能使用相同的格式,这可以通过一个叶节点来表示。但是,对于内容较多的叶节点,我们的文本存储结构可能不太适用,因为不同编码格式之间的转换可能会耗费较长时间。
当用户想在某个 Unicode 索引 = i 的位置插入新字符时,系统会执行一系列操作来处理这一请求。
- 在
ContentTree中,找到指定的Unicode index= i 的位置。 - 检查这个位置是否已有样式定位点(样式锚点)。如果没有,可以直接进行插入操作。
- 如果存在样式定位点,根据其特性选择在其左侧或右侧插入新内容。若遇到多个样式定位点,按照之前讨论的“样式边界插入文本的处理方式”进行操作。
测试
我们根据 Peritext 提出的标准进行了测试,并成功通过了所有项目。
为确保我们的 CRDTs(冲突无关数据类型)的可靠性,我们实施了大量的模糊测试。这些测试模拟了多种协作、同步和时间回溯等场景,以验证系统的最终一致性和内部运行规则的正确性。在每次关键更新后,我们会持续进行这些测试数天,确保没有遗漏任何问题。
如何使用
在使用 Loro 的富文本模块之前,需要先设置富文本样式的配置,如各种键值的展开方式和是否允许样式重叠等。
这里有一个在 JavaScript 中使用 Loro 富文本的示例:
const doc = new Loro();doc.configTextStyle({ bold: { expand: "after", }, comment: { expand: "none", overlap: true }, link: { expand: "none" }}); const text = doc.getText("text");text.insert(0, "Hello world!");text.mark({ start: 0, end: 5 }, "bold", true);expect(text.toDelta()).toStrictEqual([ { insert: "Hello", attributes: { bold: true }, }, { insert: " world!", }] as Delta<string>[]); text.insert(5, "!");expect(text.toDelta()).toStrictEqual([ { insert: "Hello!", attributes: { bold: true }, }, { insert: " world!", }] as Delta<string>[]);
总结
本文阐述了 Loro 富文本算法的设计及其实现方法。其正确性容易得到证实,且可以基于任何现有的列表型 CRDT 算法。利用 REG 和 Fugue(新标签页中打开),Loro 能够在富文本协作中融合多种 CRDT 算法的优势。
我们正在不断改进设计,并积极寻找合作伙伴。我们欢迎各种反馈和建设性的意见。如果您有合作意向,请通过 [email protected] 与我们联系。






