
这周,我参加了斯坦福大学举办的大规模故事发现数据新闻学术会议。在这样的会议上,如何从 PDF 和图片中有效提取数据始终是一个热门议题。
最近,我在使用 Gemini Pro 1.5、Claude 3 以及 GPT-4 Vision 进行实验时取得了非常令人鼓舞的成果,我会尽快分享更多详情。然而,对于大多数人来说,这些工具的使用还是有些不便。
另一方面,如Tesseract OCR等传统工具依然发挥着巨大的作用,如果它们使用起来更简单就好了。
我突然想到,得益于出色的Tesseract.js项目,Tesseract 现在可以轻松在浏览器中运行了。而且,借助 Mozilla 成熟可靠的PDF.js库,我们也可以在浏览器中处理 PDF 文件。
于是,我开发了一个新工具!
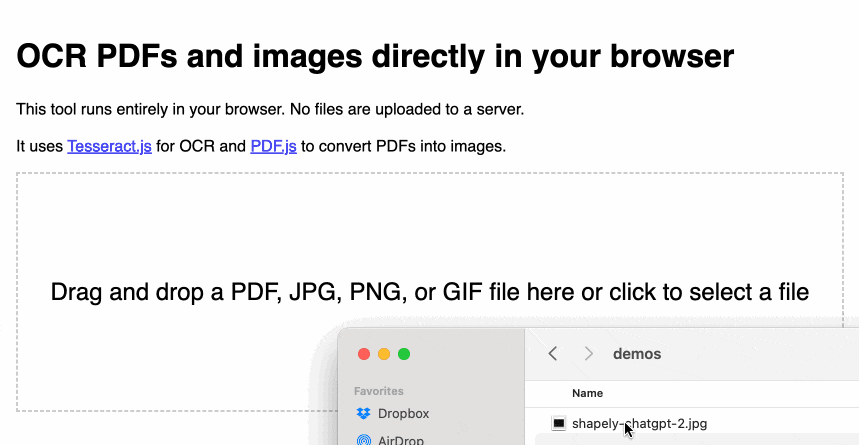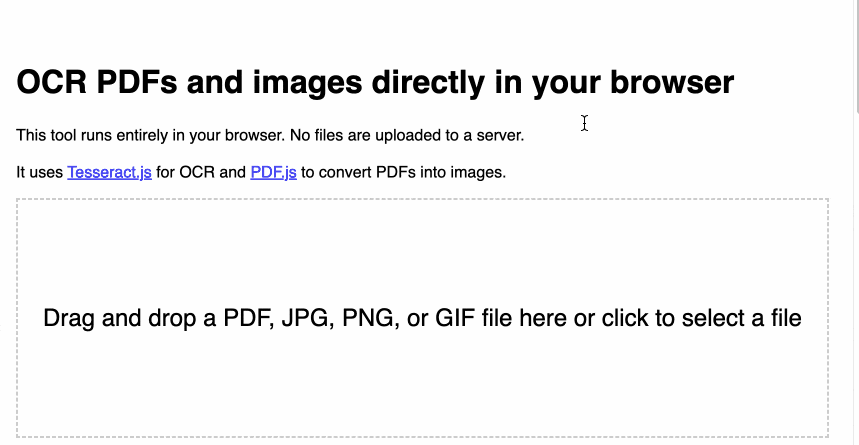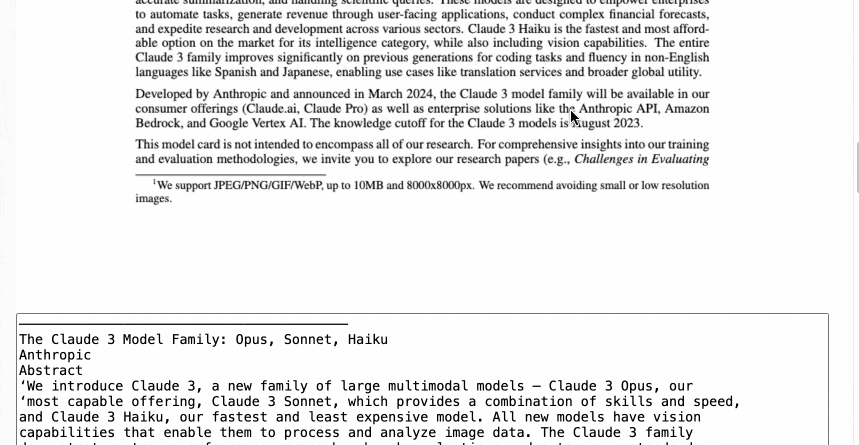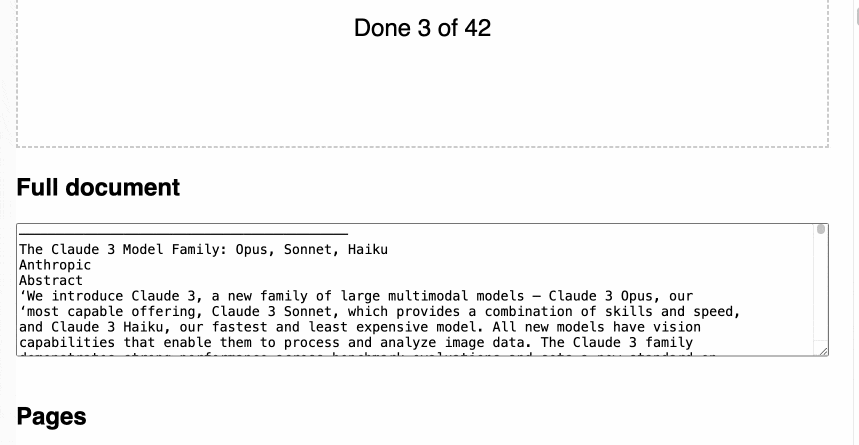
tools.simonwillison.net/ocr 这个单页网应用能够在浏览器中对打开或拖拽到应用中的图片或 PDF 文件执行 Tesseract OCR 处理。
最重要的是,所有操作都在浏览器内完成。这里不涉及服务器,也不会上传任何数据。你的图片和文档不会离开你的电脑或手机。
这里是一个动画示范:
虽然它并非完美——多列的 PDF 文件(对,谢谢学术界的“贡献”)会被当作单列处理,而插图或照片可能会变成乱码的 ASCII 图。此外,还有许多其他的边缘情况可能会导致处理失败。
但是,能在浏览器中(包括移动端的 Safari)对 PDF 使用 Tesseract OCR,依然是一项非常实用的功能。
我是怎样构建这个工具的 #
想查看更多我近期利用大语言模型 (LLMs) 创建的项目,请访问 为 SQLite 构建和测试 C 扩展以及使用 ChatGPT 代码解释器 和 利用 Claude 和 ChatGPT 执行临时任务的案例研究。
利用 Claude 3 Opus,我在短短几分钟内就开发出了这个工具的初始版本。
此前,我已经编写了一些 JavaScript 代码,完成两项关键任务:一是使用 Tesseract.js 对图片进行文字识别 (OCR),二是借助 PDF.js 把 PDF 文件转换成一连串的图片。
文字识别 (OCR) 的代码源于我之前构建并在如何制作带注解的演示中详细解释的系统,该系统是在多次 ChatGPT 会话的协助下完成的。而把 PDF 转化为图片的代码,则来自于我一周前利用 Claude 3 Opus 协助下进行的一个尚未完成的实验。
我为 Claude 3 准备了以下指令,我在里面贴入了这两段代码,并在最后附加了一些指示,说明我希望它帮我构建的内容是什么:
这段代码演示了如何打开 PDF 文件,并将其逐页转换成图片:
<!DOCTYPEhtml>
<html>
<head>
<title>PDF to Images</title>
<scriptsrc="https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.9.359/pdf.min.js"></script>
<style>
.image-container img{
margin-bottom:10px;
}
.image-container p{
margin:0;
font-size:14px;
color:#888;
}
</style>
</head>
<body>
<inputtype="file"id="fileInput"accept=".pdf"/>
<divclass="image-container"></div>
<script>
const desiredWidth =800;
const fileInput =document.getElementById('fileInput');
const imageContainer =document.querySelector('.image-container');
fileInput.addEventListener('change', handleFileUpload);
pdfjsLib.GlobalWorkerOptions.workerSrc='https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.9.359/pdf.worker.min.js';
asyncfunctionhandleFileUpload(event){
const file = event.target.files[0];
const imageIterator =convertPDFToImages(file);
forawait(const{ imageURL, size }of imageIterator){
const imgElement =document.createElement('img');
imgElement.src= imageURL;
imageContainer.appendChild(imgElement);
const sizeElement =document.createElement('p');
sizeElement.textContent=`Size: ${formatSize(size)}`;
imageContainer.appendChild(sizeElement);
}
}
asyncfunction*convertPDFToImages(file){
try{
const pdf =await pdfjsLib.getDocument(URL.createObjectURL(file)).promise;
const numPages = pdf.numPages;
for(let i =1; i <= numPages; i++){
const page =await pdf.getPage(i);
const viewport = page.getViewport({scale:1});
const canvas =document.createElement('canvas');
const context = canvas.getContext('2d');
canvas.width= desiredWidth;
canvas.height=(desiredWidth / viewport.width)* viewport.height;
const renderContext ={
canvasContext: context,
viewport: page.getViewport({scale: desiredWidth / viewport.width}),
};
await page.render(renderContext).promise;
const imageURL = canvas.toDataURL('image/jpeg',0.8);
const size =calculateSize(imageURL);
yield{ imageURL, size };
}
}catch(error){
console.error('Error:', error);
}
}
functioncalculateSize(imageURL){
const base64Length = imageURL.length-'data:image/jpeg;base64,'.length;
const sizeInBytes =Math.ceil(base64Length *0.75);
return sizeInBytes;
}
functionformatSize(size){
const sizeInKB =(size /1024).toFixed(2);
return`${sizeInKB} KB`;
}
</script>
</body>
</html>
这段代码展示了如何对图片进行文字识别 (OCR):
asyncfunctionocrMissingAltText(){
// Load Tesseract
var s =document.createElement("script");
document.head.appendChild(s);
s.onload=async()=>{
const images =document.getElementsByTagName("img");
const worker =Tesseract.createWorker();
await worker.load();
await worker.loadLanguage("eng");
await worker.initialize("eng");
ocrButton.innerText="Running OCR...";
// Iterate through all the images in the output div
for(const img of images){
const altTextarea = img.parentNode.querySelector(".textarea-alt");
// Check if the alt textarea is empty
if(altTextarea.value===""){
const imageUrl = img.src;
var{
data:{ text },
}=await worker.recognize(imageUrl);
altTextarea.value= text;// Set the OCR result to the alt textarea
progressBar.value+=1;
}
}
await worker.terminate();
ocrButton.innerText="OCR complete";
};
}
利用这些示例,你可以创建一个包含 HTML、CSS 和 JavaScript 的单页应用。这个页面会展示一个大方框,允许用户将 PDF 文件拖拽至此。完成拖拽后,PDF 中的每一页都将转换为 JPEG 格式显示在页面下方。接着,系统会使用 tesseract 对这些图片进行文字识别(OCR),并将识别结果分别展示在每张图片下方的文本框内。
我将这个操作提示保存在了 prompt.txt 文件,并通过我的 llm-claude-3 插件,在 LLM 平台上运行它:
llm -m claude-3-opus < prompt.txt
这让我在第一次尝试时就获得了一个可行的初始版本!

页面上有一个带点状边框的大方框,提示“请拖拽 PDF 文件至此”
点击这里查看完整的操作记录,其中包括了我的后续操作提示及其回应。通过这种方式对软件进行迭代调试,真是太有趣了。
首次跟进操作:
对程序进行了修改,现在它还支持通过文件选择输入——将文件拖至指定区域,可以自动填充对应的输入框。
设置拖放区域的宽度为 100%,并在页面的 body 上添加了 2em 的内边距。区域的高度设置为 10em。当拖动图片至该区域时,背景会变成粉红色。
每个文本框的宽度调整为 100%,高度为 10em。
在页面最下方,添加了一个二级标题“完整文档”,下方是一个 30em 高的文本框,里面包含了所有页面的文本内容,各页面之间用两个换行符隔开。
这里可以看到交云的结果。
PDF 文件被拖到方框上时,方框变成粉红色。“完整文档”的标题显示在下方
id:83x38ksob8seskka
令人高兴的是,它采用了一个更为简洁的设计,即文件输入被隐蔽起来,但用户可以通过点击一个大型的拖放区来激活输入。而且,它还自动更新了拖放区的提示信息,以反映新的状态——这一切都是没有经过我明确要求的。
接下来,我做了如下指示:
移除显示图片大小的代码,并将每个文本框的提示信息设置为“处理中…”。任务完成后,再清除这个提示信息。
这一改动带来了这样的版本。
我发现,如果这个工具能够同样处理非 PDF 格式的图片就更加有用了。出于好奇,我启动了 ChatGPT,看看它的表现如何,结果由 GPT-4 帮我加入了这个功能。我提交了目前的代码,并作了如下添加:
改进程序,使其能够处理 jpg、png 和 gif 格式的图片,这些图片可以直接拖放或打开——它们将跳过 PDF 处理步骤,直接被加入页面并进行文字识别。同时,将文档标题和文本框移至页面预览之上,并只有在有数据显示时才显示它们。
此外,我注意到在一个循环中多次创建 Tesseract 工作线程的做法是低效的,于是我提出了优化建议:
只创建一次工作线程,并用它来完成所有的文字识别任务,任务结束后再将其关闭。
在提交给 GPT-4 之前,我还对 HTML 和 CSS 进行了微调,现在网站不仅有了标题,而且还采用了 Helvetica 字体展示。
这是 GPT-4 帮我制作的新版本。
网站顶部的标题是“OCR a PDF or Image – This tool runs entirely in your browser. No files are uploaded to a server.”下面是一个虚线框,框内的文字提示“将 PDF、JPG、PNG 或 GIF 文件拖放至此处,或点击选择文件。”
亲手做出的完美收尾 #
尽管通过反复尝试来完善这个项目本来就充满乐趣,但我还是决定亲自动手做出一些最终的改进,以求更佳效果。这些改动可以在提交历史中查看,虽然它们看起来并不引人注目:


- 我引入了 Plausible 分析工具,我特别喜欢的一点是它不依赖 cookies 进行跟踪。
- 我优化了进度显示,现在能够包括已处理的 PDF 页数信息。
- 我把 PDF 页面图像的显示宽度从 800 像素增加到了 1000 像素,这一调整显著提升了 OCR 识别的准确率——尤其是对 Claude 3 模型卡片 PDF 来说,OCR 错误明显减少。
- 我更新了 Tesseract.js 和 PDF.js 到它们的最新版本,之前 Claude 3 Opus 项目用的是这两个库的旧版本。
这个项目让我非常满意。我认为它已经达到了完结状态——它已经实现了我最初的设计目标,我觉得没有继续修改的必要了。而且,由于整个项目都是基于静态 JavaScript 和 WebAssembly,我相信它将能够长久地、有效地运作下去。
更新: 不过,我还是添加了一些新特性:加入了语言选择功能,粘贴支持,以及使用 Playwright Python 实现的一些基础自动化测试。





